


Get Advanced Insights on Any Topic
Discover Trends 12+ Months Before Everyone Else
How We Find Trends Before They Take Off
Exploding Topics’ advanced algorithm monitors millions of unstructured data points to spot trends early on.
Keyword Research
Performance Tracking
Competitor Intelligence
Fix Your Site’s SEO Issues in 30 Seconds
Find technical issues blocking search visibility. Get prioritized, actionable fixes in seconds.
Powered by data from
Latest Blog Posts
Featured Case Studies
See what's trending before everyone else
Each week, we'll send you our best Exploding Topics. Plus, expert insight and analysis.
ChatGPT Accuracy Rate (2025 Data)

ChatGPT is getting smarter. But under every chat, there's a disclaimer: “ChatGPT can make mistakes. Check important info.”
How accurate is ChatGPT exactly? And how far should you trust it?
It's difficult to give a definitive figure because ChatGPT’s accuracy can vary depending on the question and the tools it's using.
In this article, we’ll dive into the nuances of ChatGPT’s accuracy.
Key ChatGPT Accuracy Rate Statistics
- 2025 benchmarks state that GPT-5 is accurate 91.4% of the time
- GPT-5 High has a hallucination rate of 1.4%
- Using multiple collaborative instances of GPT-4 achieved 94.7% accuracy on medical exams
- GPT-5 scores a perfect 100% on the High School Math (AIME 2025) benchmark
ChatGPT Accuracy Rate
According to the latest Massive Multitask Language Understanding (MMLU) benchmark, ChatGPT has a 91.4% accuracy rate.
Here's how that compares to human accuracy and the accuracy of competing LLMs:
| Method Evaluated | MMLU Benchmark 2025 |
| GPT-5 | 91.4% |
| GPT-4.1 | 90.2% |
| Human experts | 89.8% |
| GPT-4o | 88.7% |
| o3 | 88.6% |
| Claude Opus 4 | 87.4% |
MMLU is considered to be the gold standard in LLM measurement. It was developed in early 2021 as a way to quantify large language model intelligence.
The test includes 15,908 questions sourced from exams and tests across humanities, social sciences, STEM, and applied fields like medicine. In total, the test involves 57 different subject areas.
Factors Affecting ChatGPT’s Accuracy
GPT-5's performance is impressive. In the High School Match (AIME2025) test, it scores a perfect 100%.
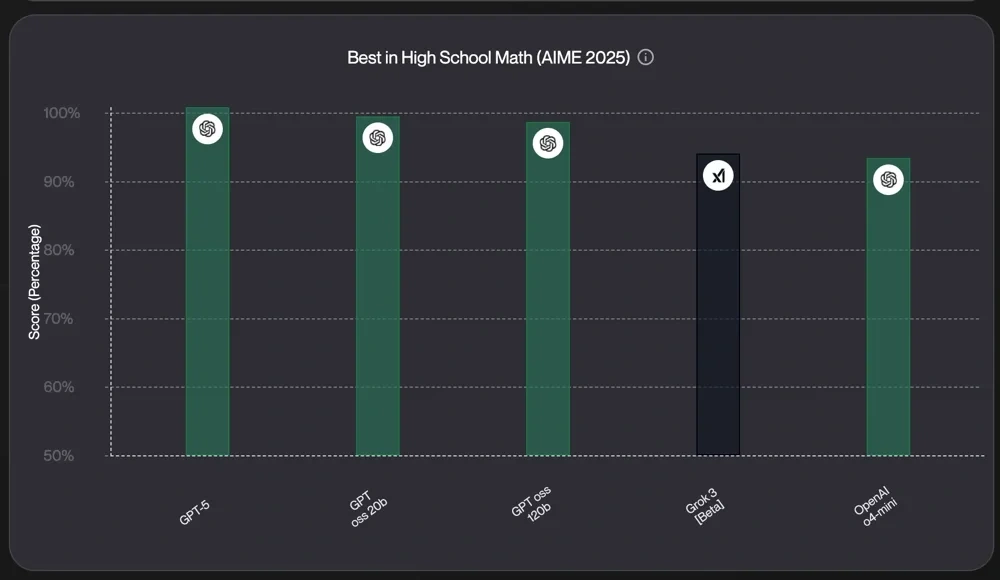
But it's important to remember that LLM performance is variable across subject areas. In MMLU, it achieved extremely high accuracy in social sciences, but scored much lower in domain-specific areas.
This pattern is not new. When GPT-3 was tested, its accuracy rate was only around 25%, which is close to the accuracy of a randomly selected answer, or a non-expert human.
ChatGPT’s accuracy varies based on several other factors:
- Vague prompts are more likely to produce inaccurate responses.
- Model cutoff dates impact accuracy, since the model only knows information up to a certain date.
- Accuracy is better in English for ChatGPT. The more obscure a language (in technical terms, the fewer resources it has for training data), the worse ChatGPT will perform.
- New benchmarks are tougher. Modern benchmarks use adaptive difficulty to present progressively more difficult questions. Other benchmarks specialize in specific subject areas like medicine or law.
- Thinking mode sometimes improves results. A model that can think takes longer to respond but can deliver more accurate information.
- Tests can contain mistakes. The MMLU test is not perfect. For example, some questions are said to be ambiguous. So a score of 100% is not possible, even if a human takes the test.
GPT-5 was deliberately made less intelligent in training (Windows Central)
OpenAI said that GPT-5 has been trained on less data than previous models, making it less accurate without access to tools.
Instead of the model containing as much information as possible, it's is designed to use search and reason to reach the correct answer.
Sam Altman says the perfect AI is “a very tiny model with superhuman reasoning, 1 trillion tokens of context, and access to every tool you can imagine.”
— vitrupo (@vitrupo) June 3, 2025
It doesn't need to contain the knowledge - just the ability to think, search, simulate, and solve anything. pic.twitter.com/kuY1Z0Zhbw
Developing smaller models is less expensive for OpenAI, and partly sidesteps the issue of running out of new data to train on.
As it focuses more on tools, OpenAI can explore using new data sources like ChatGPT apps.
ChatGPT Hallucination Rates
Like all LLMs, ChatGPT sometimes hallucinates a response, which means it provides a plausible answer that is not accurate.
But newer models do not necessarily hallucinate less. And smaller models can be more accurate than larger ones.
o3 Mini High Reasoning Has the Lowest Hallucination Rate Among OpenAI Models
One way of measuring hallucinations is the Hughes Hallucination Evaluation Model, which measures how frequently a model adds incorrect information to a document summary.
The selected hallucination rates below were published on the Vectara Leaderboard on October 13, 2025.
| Model | Hallucination % |
| o3 Mini High Reasoning | 0.795 |
| GPT-5 High | 1.4 |
| o1 Mini | 1.4 |
| GPT-4o | 1.491 |
| GPT-4 | 1.805 |
| GPT-3.5 Turbo | 1.925 |
| GPT-4.1 | 2 |
| Grok 3 | 2.1 |
| o1-pro | 2.4 |
| o1 | 2.4 |
| GPT-5 Mini | 3.2 |
| Grok 4 | 4.8 |
| Claude Opus 4 | 4.8 |
| o3 | 6.8 |
| DeepSeek r1 | 7.7 |
OpenAI has its own internal tests to determine hallucination rates: SimpleQA and PersonQA.
In the GPT-5 system card, OpenAI said tests found GPT-5 hallucinated less than o3.
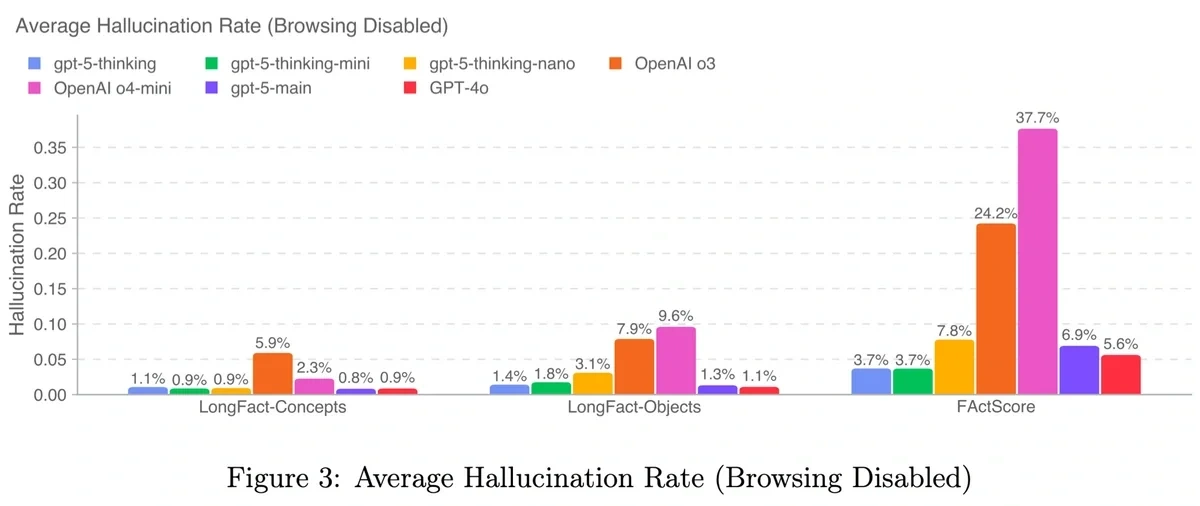
OpenAI found that hallucinations worsen for uncommon facts (OpenAI)
OpenAI found that ChatGPT is more accurate when it sees the same fact multiple times in training.
One example is that if 20% of famous dates only appear once in training, the hallucination rate when asked about that topic is likely to be 20%.
The need to ensure facts are repeated is important for businesses that are looking to improve brand visibility in LLMs.
Build a winning strategy
Get a complete view of your competitors to anticipate trends and lead your market
The study proposed a number of ways to improve accuracy in LLMs:
- Train ChatGPT to say "I don't know" more frequently instead of rewarding guesswork
- Eliminate "GIGO" (garbage in, garbage out), or factual errors in training data
However, it notes that context engineering, grounding, or RAG can help ChatGPT to be more accurate. But they will not solve hallucinations entirely.
ChatGPT is more accurate when it collaborates with itself (PLOS Digital Health)
ChatGPT has become successively better at tackling the United States Medical Licensing Examination. The USMLE is a difficult three-exam program that is required for a doctor of medicine to get their license.
Early models of ChatGPT achieved just 36.7% accuracy in the USMLE. GPT-3 reached 46% accuracy, a figure that rose to 50% with some training.
However, when researchers used 5 separate instances of GPT-4 to form a "Council of AIs", the group of LLMs achieved an overall accuracy rate of 94.7%. The researchers had instructed the LLMs to discuss the problem if they did not initially agree, suggesting that deliberation could improve accuracy.
However, when all GPT-4 instances got the initial answer wrong, they were unable to reach an accurate answer.
ChatGPT’s Accuracy Over Time
ChatGPT’s accuracy can change over time (ARXIV)
ChatGPT’s accuracy can markedly decrease or improve depending on other changes to the model. These changes in accuracy are called AI model drift.
In 2023, Stanford and UC Berkeley researchers found that GPT-4's accuracy in identifying prime numbers dropped sharply from 97.6% in March 2023 to just 2.4% by June 2023.
Researchers believe that the model became less effective at following chain-of-thought prompts.
But the same study found that GPT-3.5 was actually far more accurate at identifying prime numbers in June 2023 than in March 2023.
The researchers in this study noted that these changes indicate the need for “continuous monitoring of LLMs” like ChatGPT.
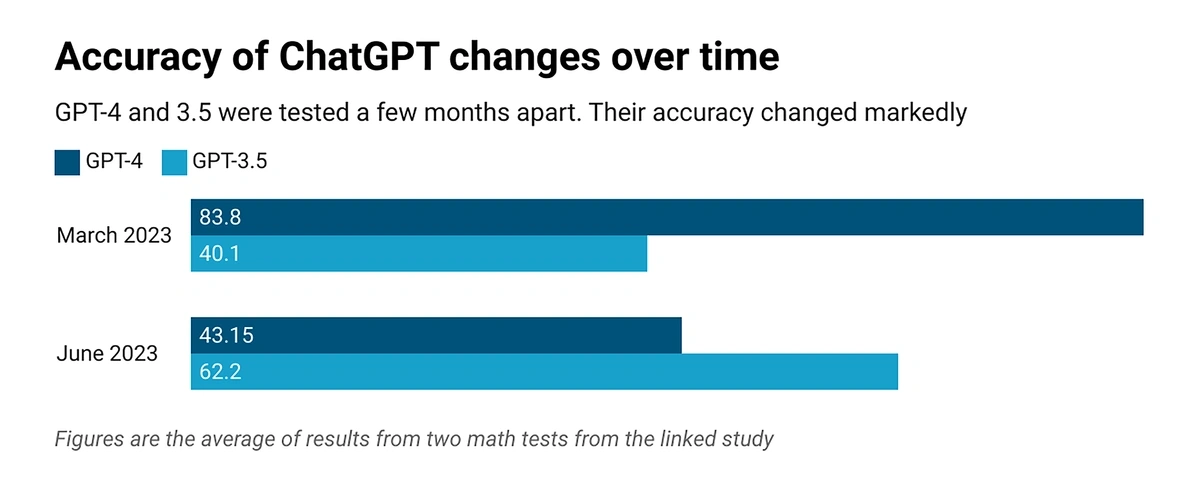
GPT-4o is 3.1% less accurate than GPT-4 Turbo at reading comprehension (OpenAI)
OpenAI’s DROP (f1) test involves answering complex questions. Accuracy requires a high level of reasoning.
While GPT-4 Turbo scored 86 points, GPT-4o scored 83.4. That also makes GPT-4o less accurate at reading comprehension than Llama3 400b, though only by 0.1 points.
OpenAI o3 achieved the highest publicly listed DROP F1 score at 89.8 points (3-shot).
Get More Search Traffic
Use trending keywords to create content your audience craves.
ChatGPT’s Precision
Precise means giving the same answer every time. Accurate means giving the correct answer.
With AI tools, high precision means a lower likelihood of generating false positives. For example, an imprecise chatbot might answer a query incorrectly but mark that query as successfully resolved. This would be a false positive.
GPT-4o has a precision of 86.21% (Vellum)
GPT-4o has a precision of 86% on classification tasks (tested on customer support ticket classification).
In more recent testing comparing OpenAI o1 vs GPT-4o vs Claude 3.5 Sonnet, GPT-4o still shows 86% precision, with o1 at 72% precision and Claude 3.5 Sonnet at 79% precision.
GPT-4 and GPT-3.5 are more precise than Gemini (PubMed)
The three AI models were tasked with conducting systematic reviews, which is the generation of scientific citations. ChatGPT-3.5 had a precision rate of 9.4%, GPT-4 had 13.4%, while Gemini (then called Bard) scored 0%.
ChatGPT’s Accuracy in Medical Topics
ChatGPT-3.5 is 84.8% accurate at neurolocalization (CureUs)
In 2023, ChatGPT-3.5 was tested on various questions relating to neurolocalization, or the diagnosis of conditions affecting the nervous system. A team of seven neurosurgeons evaluated the model’s responses, concluding that it had generated “completely correct” or “mostly correct” answers 84.8% of the time.
ChatGPT-4 is more accurate than the average human in medical exams (OpenAI)
OpenAI conducted extensive testing on GPT-4 before its release. The model undertook various tests, including the Medical Knowledge Self-Assessment Program Exam. Its performance varied, though it was often better than human candidates. For example, it scored 64% on the Specialty Certificate Examination Neurology Web Question Bank. In comparison, the average score of the human candidates who took that exam was 60.2%.

ChatGPT achieved a median accuracy score of 5.5 out of 6 when answering medical questions (JAMA Network)
In October 2023, a group of researchers tested the performance of GPT-3.5 and GPT-4 on a collection of 284 medical questions. The questions were generated by a group of 33 physicians. Answers were scored on a scale of 1 to 6, where 6 is completely correct.
ChatGPT achieved a median score of 5.5 across all questions, and a mean score of 4.8. On easy questions, it achieved a median score of 6.0, while hard questions resulted in a median score of 5.0.
ChatGPT-3.5 was 86.6% accurate when diagnosing common urological conditions, better than Google (MDPI)
This study, published in May 2024, compared ChatGPT-3.5 with Google Search for diagnosing urological conditions. Google Search had an accuracy of just 53.3% when tackling commonly encountered conditions, while ChatGPT-3.5 scored 86.6%.
ChatGPT-3.5 fared significantly worse when evaluating unusual disorders. It provided accurate responses just 16.6% of the time.
ChatGPT-3.5 had a median accuracy of 4 out of 6 when responding to medical test results, worse than Copilot (Nature)
This study was published in April, 2024. ChatGPT-3.5, Copilot, and Gemini were tested on their responses to the results of certain urea and creatine test results. Both GPT-3.5 and Gemini scored a median of 4 out of 6. Copilot scored a median of 5.
ChatGPT was less than 66% accurate at identifying drug-drug interactions, worse than BingAI and Gemini (Bard) (PubMed)
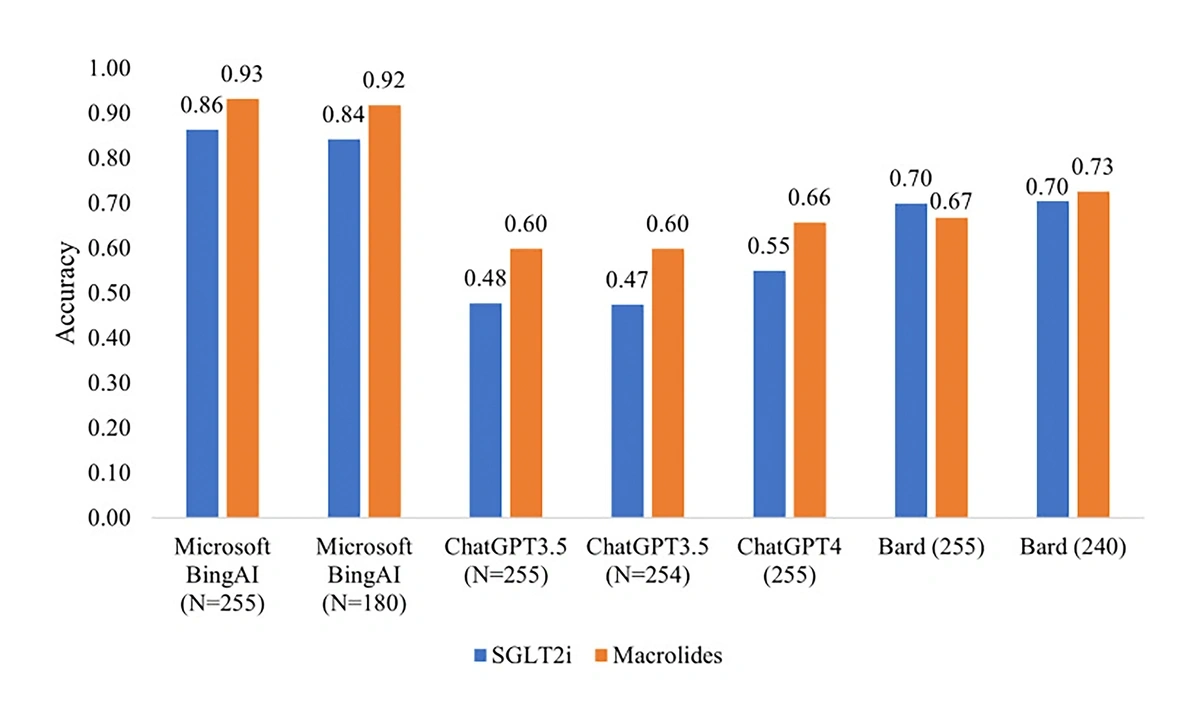
ChatGPT is 72% accurate in clinical decision-making across all medical specialties (Mass General Brigham)
This study, published in August 2023, tested ChatGPT in a variety of clinical situations. It had to make similar decisions to human healthcare professionals. Overall, its responses were 72% accurate.
ChatGPT performed best at making final diagnoses, achieving 77% accuracy. It was less accurate when making clinical management decisions — for example, choosing what medications to use after deciding on a diagnosis — with just 68% of its responses being accurate.
ChatGPT is just 60% accurate at making differential diagnoses (Mass General Brigham)
A differential diagnosis is a situation where a clinician must differentiate between multiple possible conditions that present similarly. They are often difficult calls to make, and it is therefore unsurprising that ChatGPT struggled. Just 60% of its attempts were accurate.
According to one of the researchers involved in this study, this result “tells us where physicians are truly experts and adding the most value.”
ChatGPT answered 77.5% of medical questions correctly (Nature)
In this study, published in Nature in January 2024, ChatGPT-3.5 was tested on 120 questions relating to disease management. It managed to answer 77.5% of the questions correctly. However, only 61.7% of its responses were both correct and complete per professional guidelines.
Interestingly, the researchers noted that ChatGPT performed better in some topics than others. They hypothesized that this may be due to differing volumes of information about different topics in ChatGPT’s training data.
ChatGPT achieved more than 50% accuracy across all US Medical Licensing Examination exams (MedRXIV)
The USMLE is a program consisting of three exams. Success is required for an individual to become a licensed doctor of medicine. In one study, published in December 2022, ChatGPT performed well on all of the three exams in the USMLE. It was more than 50% accurate in all of the exams, and often surpassed 60% accuracy. While the passing threshold varies by year, it’s usually around 60%.
In 2025, researchers increased this to 94.7% accuracy by using a multi-agent framework of GPT-4 instances that were required to discuss their answers.
ChatGPT’s Accuracy vs Other AI Models
ChatGPT-4o is 99% accurate at classification, better than competitors (Lars Wiik)
In May 2024, LLM engineer Lars Wiik tested ChatGPT-4o on a dataset he created himself. The dataset consisted of 200 sentences, each categorized into one of 50 topics. The test involved correctly assigning a sentence to its topic. ChatGPT-4o made just two errors. ChatGPT-4o was the most accurate, beating previous versions of ChatGPT and Gemini.

ChatGPT is more accurate than PubMedGPT on a key medical exam (MedRXIV)
A study published in December 2022 found that ChatGPT often achieved over 60% accuracy on the United States Medical Licensing Examination. Interestingly, this was more accurate than PubMedGPT, which was just 50.8% accurate. PubMedGPT is similar to ChatGPT, but was only trained on scientific materials. According to the authors of the study, ChatGPT’s advantage may have come from being “exposed to broader clinical content … that [is] more definitive,” rather than only being trained on often-inconclusive or ambivalent scientific literature.
ChatGPT-4o is more accurate than Claude, Gemini, and Llama in four key tests (OpenAI)
When OpenAI released ChatGPT-4o, they trumpeted its strong performance in six tests often applied to LLMs. In some cases, GPT-4o’s performance was only marginally better. For example, it achieved 88.7% accuracy in the MMLU. That is just 0.9% better than Claude3 Opus, and just 2.6% better than Llama3 400b.
In other cases, GPT-4o demonstrated substantial improvements in accuracy. In the MATH test, GPT-4o achieved 76.6% accuracy. That is around 20% better than both Gemini Pro 1.5 and Gemini Ultra 1.0.
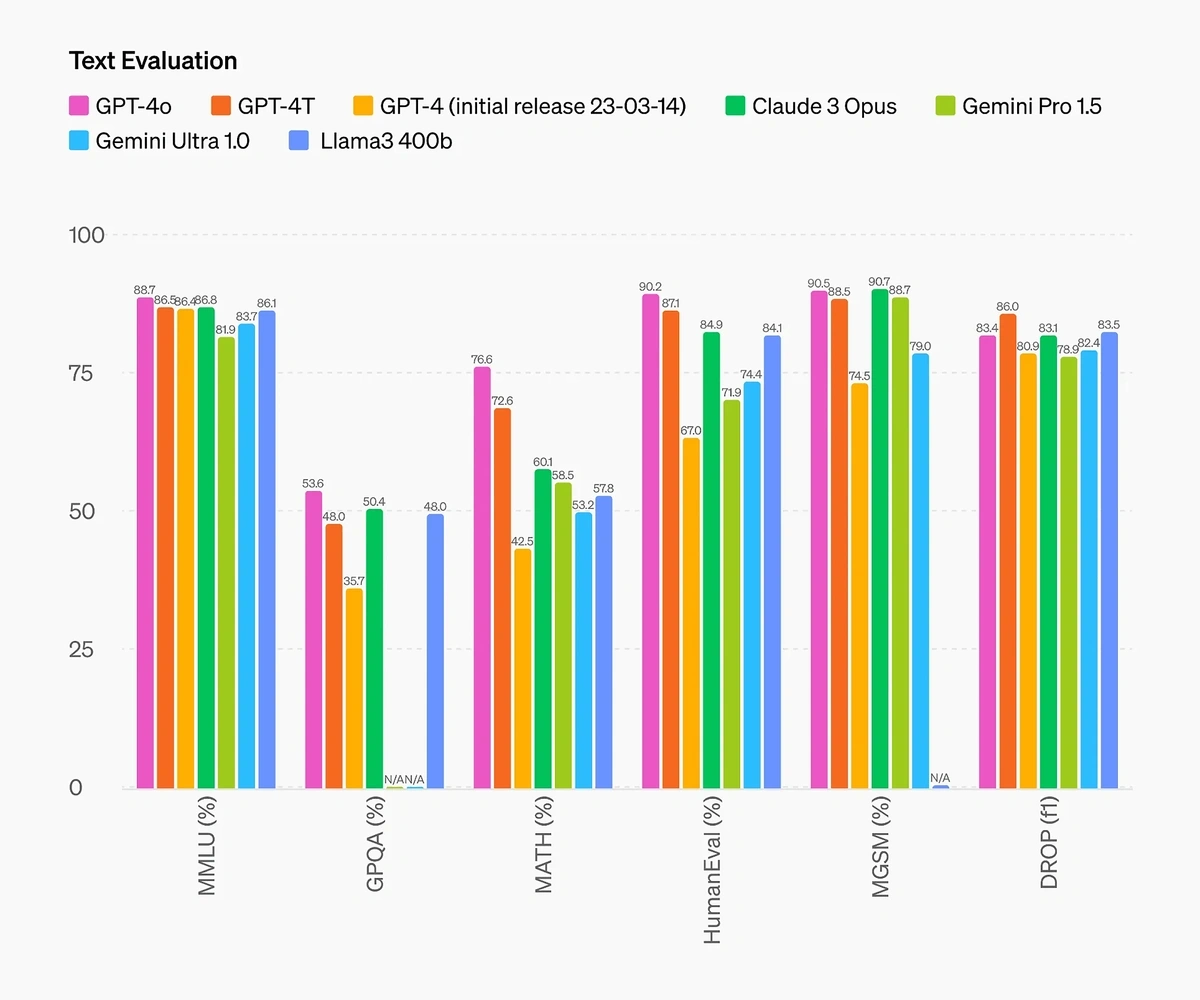
But it sometimes is less accurate (OpenAI)
As you can see from the graph, GPT-4o wasn’t always more accurate than competitors. In the Multilingual GSM8K test (MGSM) — comprised of arithmetic problems in different languages — GPT-4o was only slightly less accurate than Claude3 Opus.
ChatGPT’s Accuracy in Different Languages
As we’ve discussed before, ChatGPT is still fundamentally an English tool. Multiple studies have demonstrated that ChatGPT performs best in English. In other languages, particularly those with fewer resources — material on which the model can train — ChatGPT struggles.
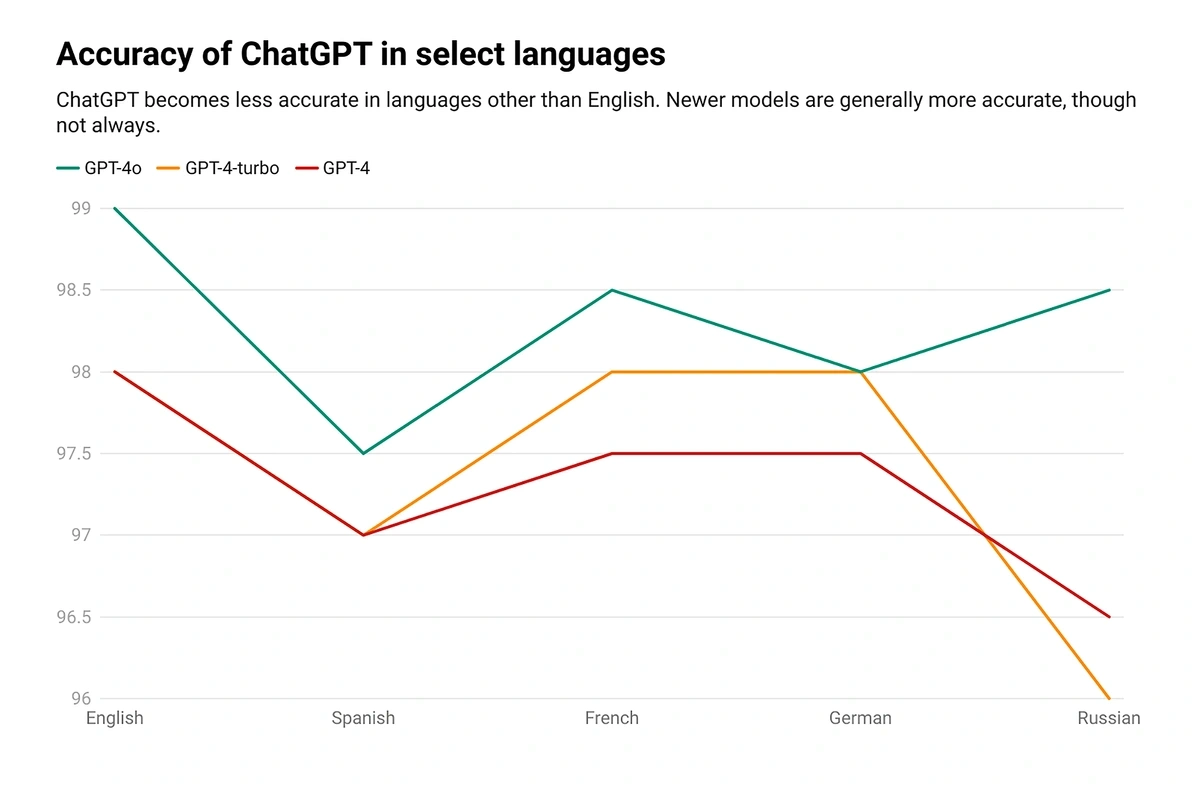
ChatGPT-4o is 99% accurate in English, but slightly less accurate in other languages (Lars Wiik)
Lars Wiik, an LLM engineer, tested various AI models on a dataset that was translated from English into various European languages. The results suggested that ChatGPT is generally very accurate, and that newer models are more accurate than older ones — although this isn’t always true. In Russian, for example, GPT-4 Turbo underperformed.
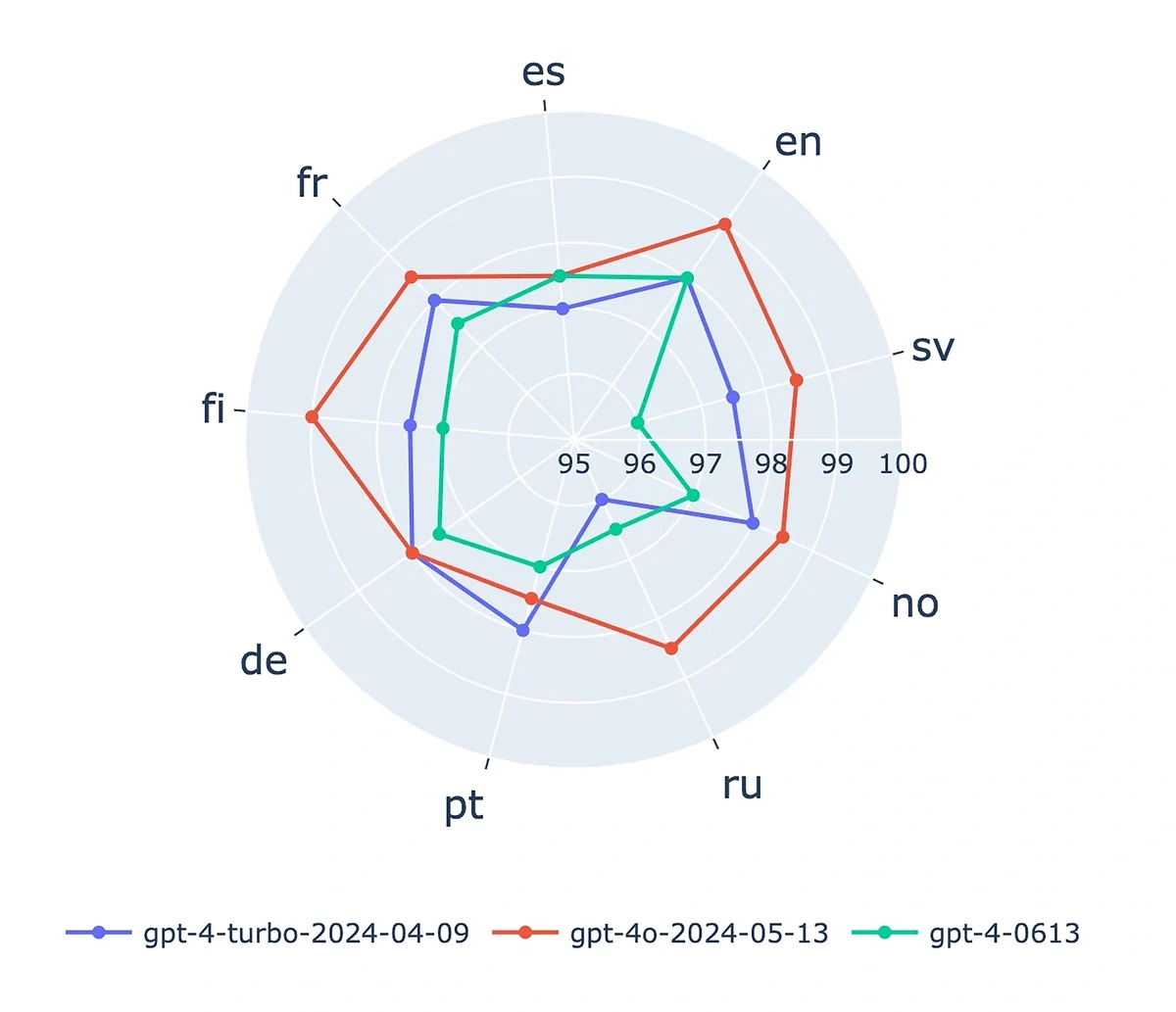
ChatGPT-4o is 1-2% less accurate than competing AIs in non-English languages (Lars Wiik)
Wiik also tested some of OpenAI’s top competitors on the same dataset. ChatGPT-4o was comparable to Gemini 1.5. GPT-4o was more accurate in English, Russian, Finnish, and the two were even in Norwegian. However, Gemini was more accurate in Spanish, French, German, Dutch, and Portuguese.
More importantly, Claude 3 Opus outperformed GPT-4o in every language except Norwegian, where the two drew.
ChatGPT’s Accuracy at Non-Text Tasks
Originally, AI tools like ChatGPT were unimodal. That means they could only deal with text. While we are still waiting for a truly multimodal AI tool, recent models, like GPT-4o, have implemented some multimodal features.
However, some reports indicate that ChatGPT may be less accurate at these visual tasks.
ChatGPT-4’s accuracy can drop to 50% when answering image queries (OpenAI Community)
In March 2024, a user on the OpenAI forums reported encountering a curious problem. They had been using GPT-4’s vision preview model to power a bot that interpreted and answered questions sent to it in image format. Initially, the bot answered questions with 80 to 90% accuracy. But according to the user, one day the accuracy cratered to 50%.
Other users were unsure why this might be the case. One user recounted rumors that ChatGPT would become “lazy” at times. This could be related to research demonstrating that ChatGPT’s accuracy can change over time.
Conclusion
Ultimately, ChatGPT’s accuracy varies by a large degree. Much of this variation is out of your control. However, there are ways to improve accuracy, such as submitting more specific prompts.
While ChatGPT has been shown to sometimes become less accurate over time, its accuracy has generally improved markedly in the few years since its initial release.
Continuing to improve model accuracy will likely be central to the ongoing competition between OpenAI and its competitors.
Therefore, ChatGPT may well become even more accurate in the future.
Stop Guessing, Start Growing 🚀
Use real-time topic data to create content that resonates and brings results.
Exploding Topics is owned by Semrush. Our mission is to provide accurate data and expert insights on emerging trends. Unless otherwise noted, this page’s content was written by either an employee or a paid contractor of Semrush Inc.
Share
Newsletter Signup
By clicking “Subscribe” you agree to Semrush Privacy Policy and consent to Semrush using your contact data for newsletter purposes
Written By


Josh is the Co-Founder and CTO of Exploding Topics. Josh has led Exploding Topics product development from the first line of co... Read more