


Get Advanced Insights on Any Topic
Discover Trends 12+ Months Before Everyone Else
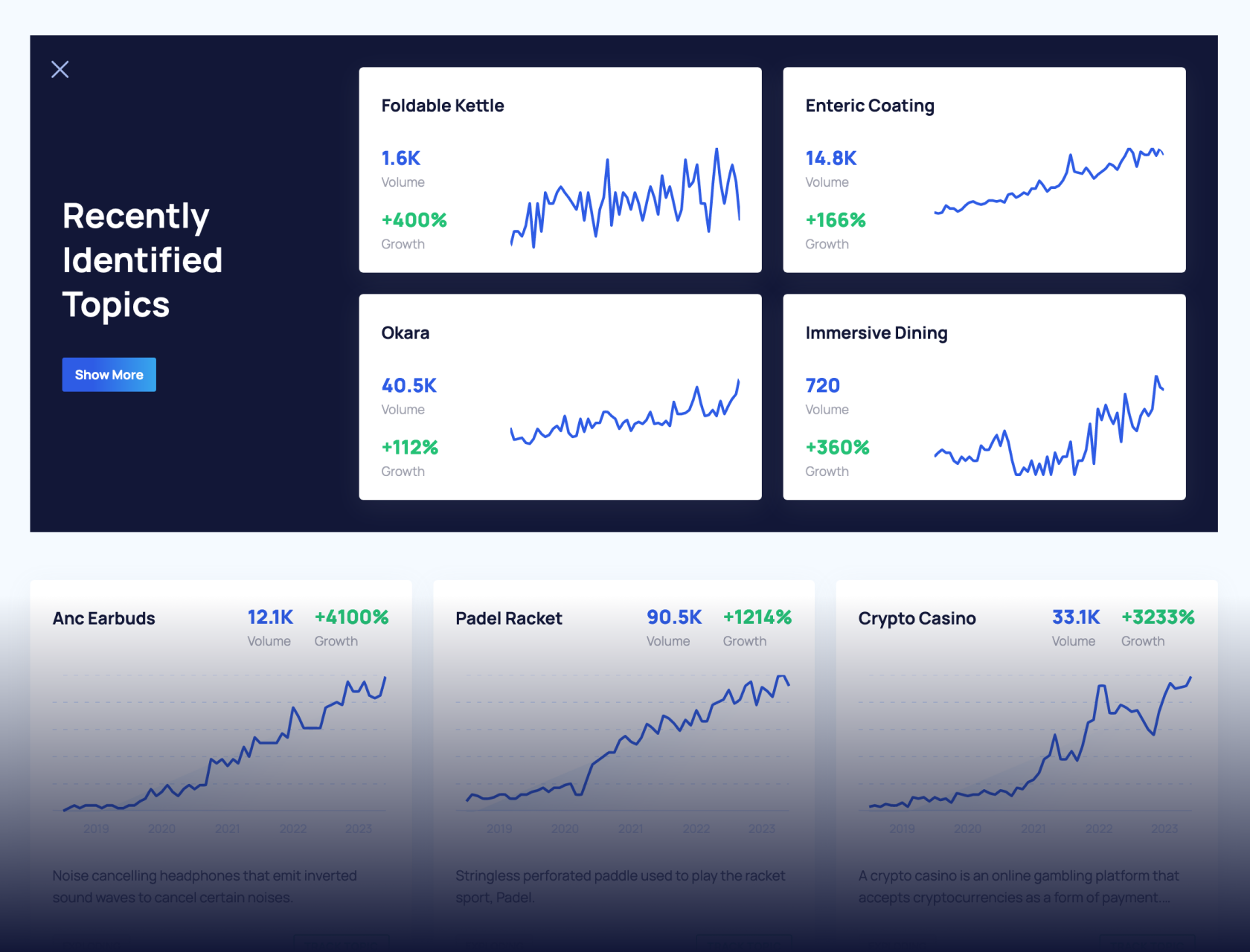
How We Find Trends Before They Take Off
Exploding Topics’ advanced algorithm monitors millions of unstructured data points to spot trends early on.
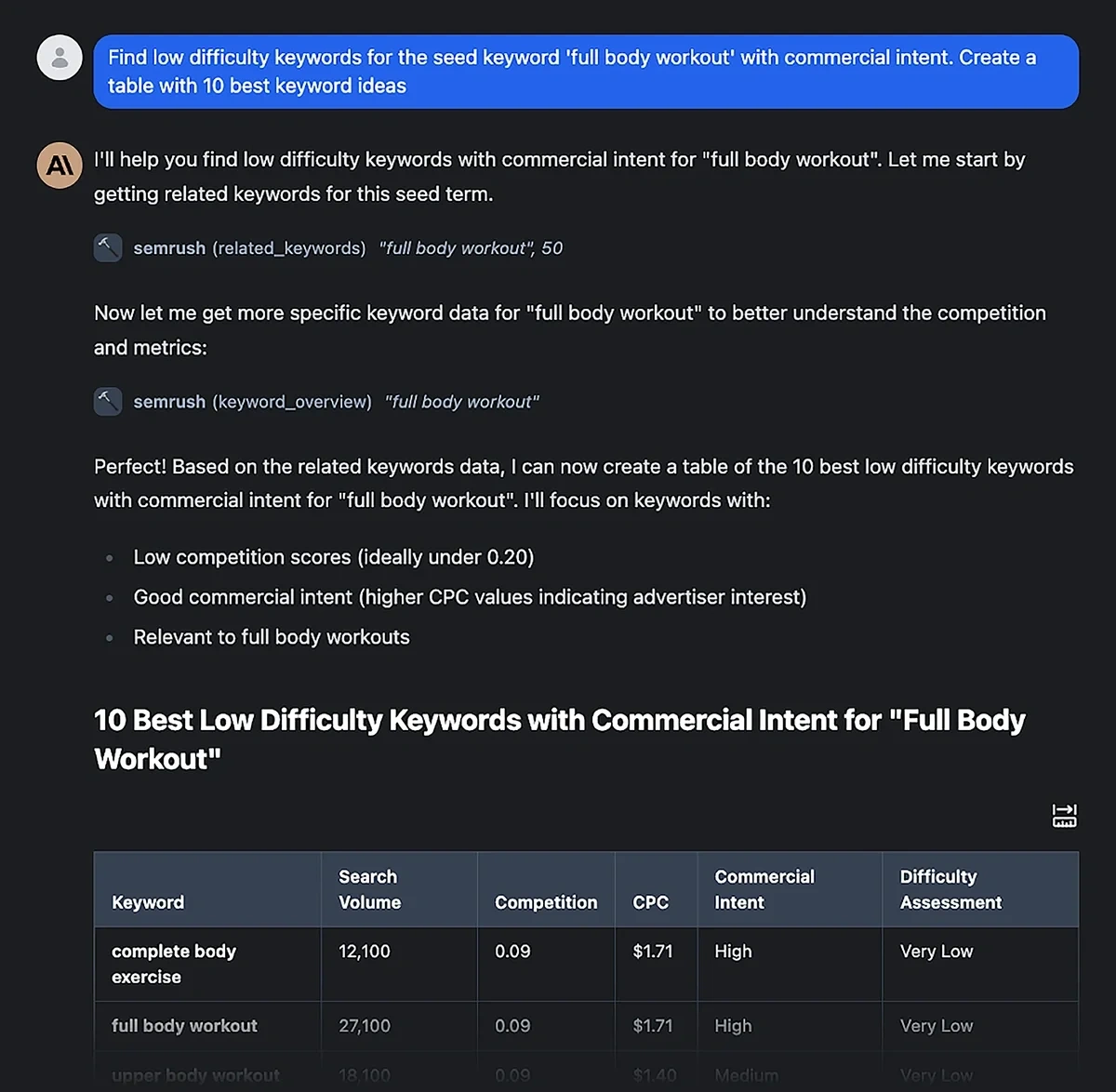
Keyword Research
Performance Tracking
Competitor Intelligence
Fix Your Site’s SEO Issues in 30 Seconds
Find technical issues blocking search visibility. Get prioritized, actionable fixes in seconds.
Powered by data from
Latest Blog Posts
Featured Case Studies
See what's trending before everyone else
Each week, we'll send you our best Exploding Topics. Plus, expert insight and analysis.
Context Engineering Rises as Million-Token Context Windows Show Diminishing Returns

Context engineering is the practice of systematically providing AI models with relevant background information and data sources to improve the contextual accuracy of the response.
Searches for “context engineering” are rising explosively. And the surge makes sense: AI models are getting smarter, use cases are more complex, and users are more familiar with prompting techniques to get the most meaningful results.
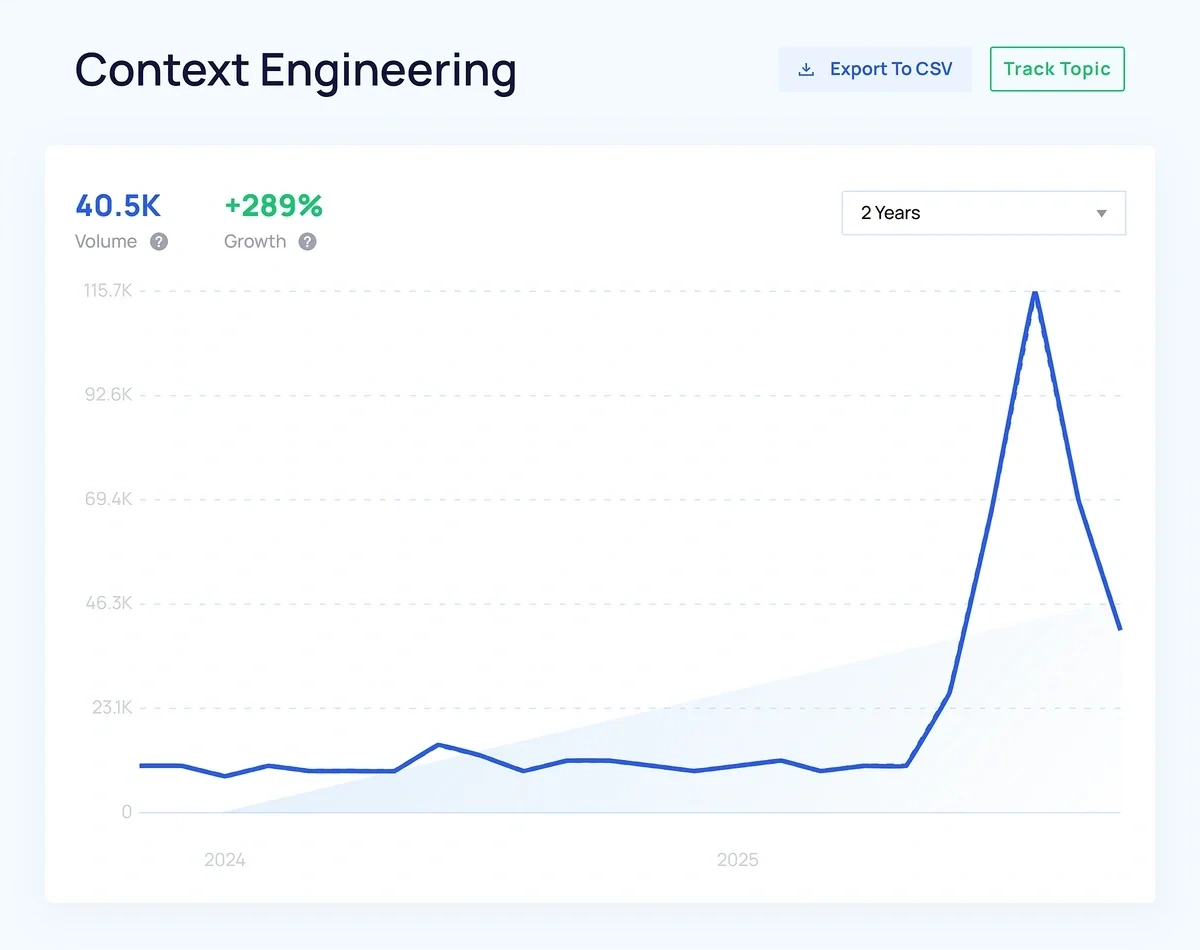
All of that is giving rise to the need to supply context to AI in strategic ways that aren’t only focused on how cleverly worded your prompt is.
Unlike prompt engineering, context engineering combines requests with broader contextual knowledge from external tools, memory, and data sources.
For tasks requiring precision, context engineering typically outperforms clever prompting alone.
Let’s explore key factors driving this shift toward contextually-aware AI tools, take a look at examples, and consider whether context-heavy AI interactions are about to become standard.
RAG Technology Dominates for Context-Aware AI
Information retrieval is one of the key components of context-engineered AI systems.
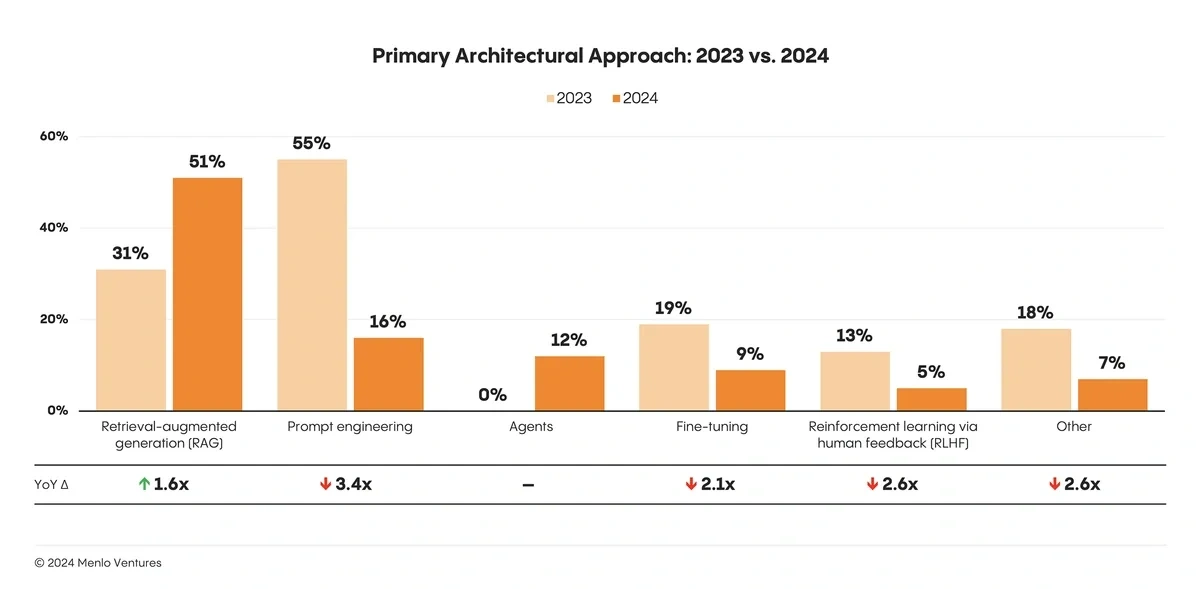
Recent trends show that approaches to AI systems design are increasingly focusing on retrieval augmented generation (RAG) workflows for applications where high contextual awareness is needed.
RAG reached a market size of $1.2 billion in 2024, with some estimates projecting $11.2 billion by 2030.
To define the concept simply, RAG is when an AI model accesses new information from external sources outside its training data to generate a reliable, up-to-date answer.
In 2024, RAG also reached up to 51% adoption in enterprise AI design patterns.
One of the strongest endorsements of RAG-based design came with OpenAI’s latest model: ChatGPT 5.
Unlike earlier models, ChatGPT 5 took a step back in terms of its breadth of training knowledge. In other words, it’s more ignorant.
Instead, ChatGPT 5 favors combining intelligence and reasoning abilities with knowledge obtained from sources like the web.
An AI model doesn’t need to know everything. It can rely on the web to access the information it needs for context.
With that, ChatGPT has reaffirmed context engineering as the core principle for high-quality answer generation.
At the same time, NotebookLM is rising in popularity, a tool that’s fundamentally built around RAG.
It specializes in pulling context from a collection of data sources.
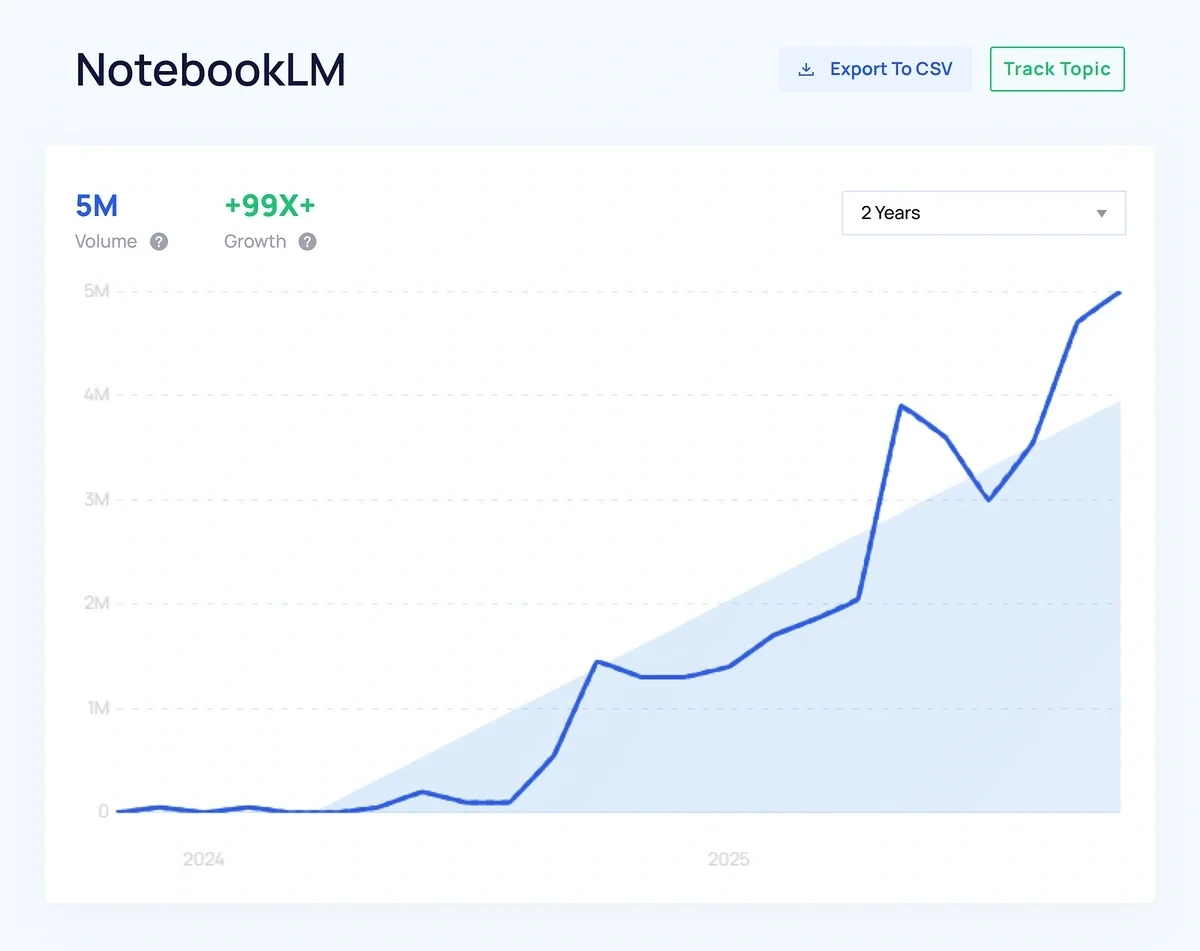
These developments point to RAG-driven features—and context engineering, as a result— playing a more central role in current and upcoming top AI models
But there’s another trend taking shape that some AI developers see as a challenge to context engineering: long context LLMs.
Is Context Engineering at Odds with the Rise of Long-Context LLMs?
Current AI models significantly outperform earlier counterparts in terms of maintaining long context accuracy.
With every successive generation of AI models, extended context sizes are now a common theme.
The original GPT-3.5 model only had a context window of 4,000 tokens.
Since then, context windows have increased dramatically for the most powerful AI models.
GPT 4.1 launched with extended context windows of up to 1 million tokens.
Google also started offering context windows as high as 2 million tokens with Gemini 1.5 Pro.
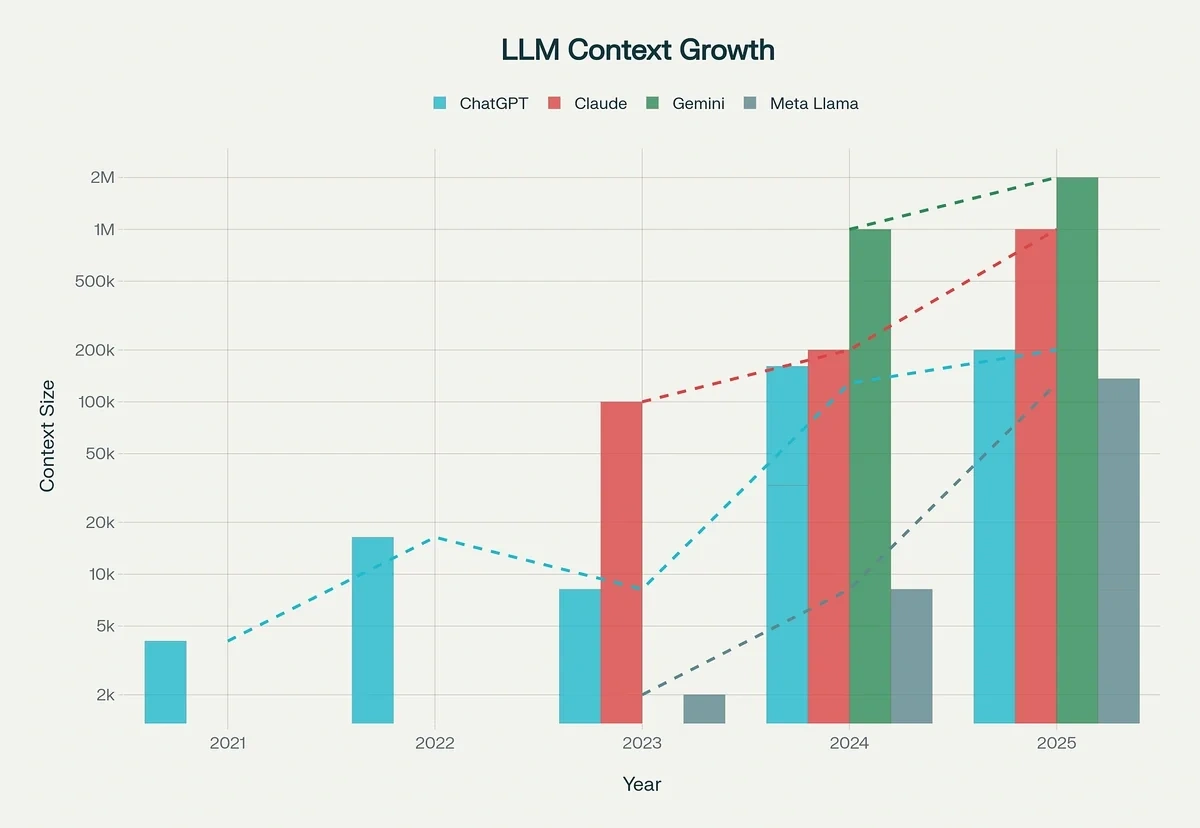
It’s a strong indication that long-context LLMs are a design priority for most mainstream AI companies today.
This means that AI tools can process a huge amount of context all at once, directly with the user’s input query.
But then, the question arises:
Is engineering for context really necessary when you can frontload all the required context in a single prompt rather than building context from several different sources?
In other words, aren’t you better off just carefully crafting prompts like prompt engineering approaches suggest?
The answer is that the relationship between large context windows and the accuracy of AI responses is far from simple.
Long Context Size Isn’t Necessarily Better
Most LLMs can deliver more reliable answers when their context limitations are sufficiently large.
However, performance degrades sharply when context exceeds a certain point.
The performance drops occur sooner for older models like GPT-3.5 and Meta Llama 3.
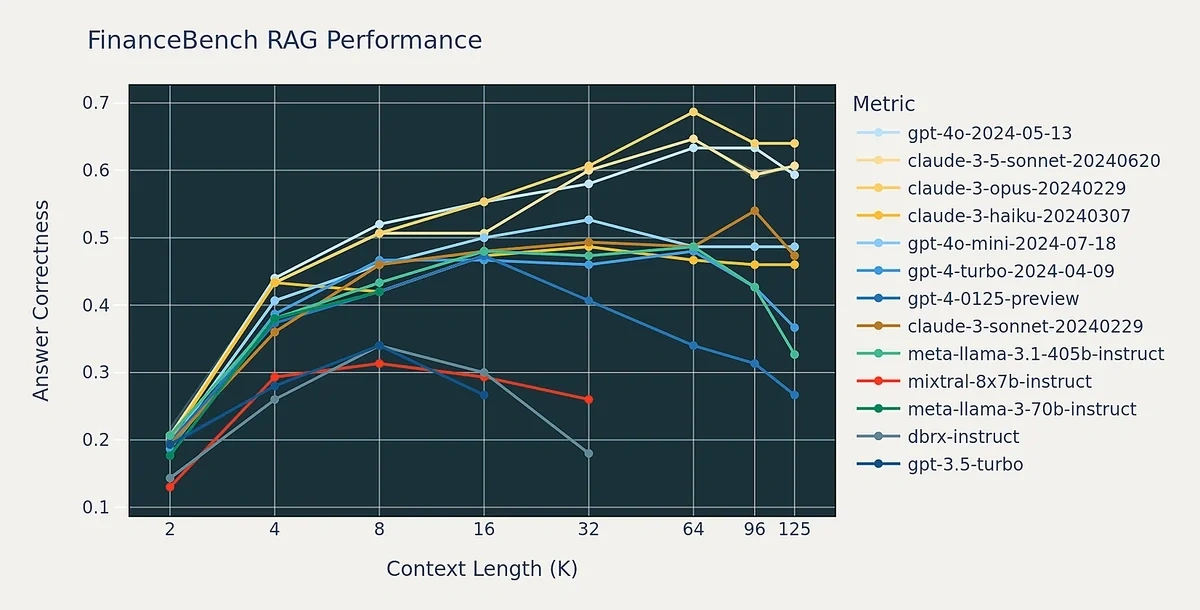
Newer models like GPT-4o and beyond maintain performance as context length increases.
But even powerful models with massive context windows aren’t immune to context failures.
Gemini 2.5, with a 1 million+ token context size, struggles to make effective use of it.
In fact, after 100k tokens of context, the model started relying too much on past context rather than generating new solutions.
These examples show that long-context LLMs can fail by:
- Getting distracted by too much context built over historically
- Repeatedly referencing a hallucination for future outputs
- Inability to ignore irrelevant context
- Struggling to reconcile conflicting context introduced in stages
Other studies also suggest that even when a model uses long context, the resulting performance gain is marginal at best.
The returns get diminishing, and the curve flattens.
The added latency and costs of processing huge chunks of context can also become prohibitive for more complex use cases, especially at the enterprise level.
Since RAG systems are based on retrieving only the relevant context, they need a much shorter context size to generate accurate and tailored responses.
This is why many AI researchers see a hybrid architecture (RAG + long context), as the solution for ideal AI performance.
We have ChatGPT 5 giving serious weight to this idea now that it’s reverting to lower context lengths than GPT 4.1
With ChatGPT’s greater reliance on contextual retrieval than on upgrading context size, we might see the race for ballooning context sizes slow down a bit.
Best Tools for Context Engineering
Recently, top AI tools have launched several features to assist users in providing structured context that the model can use to generate more meaningful responses.
Here are a few tools that I think have the right feature set to support contextual understanding beyond direct input prompts:
1. ChatGPT
ChatGPT has several features that let you set up context for specific tasks.
First, you can create a dedicated project.
This is essentially a workspace for organizing related chats on a single topic and ignoring everything outside the boundaries of the context you set up in the project.
You can give a system-level instruction to ChatGPT to guide its response and behavior.
These are instructions that the model will follow across all chats in the same project.
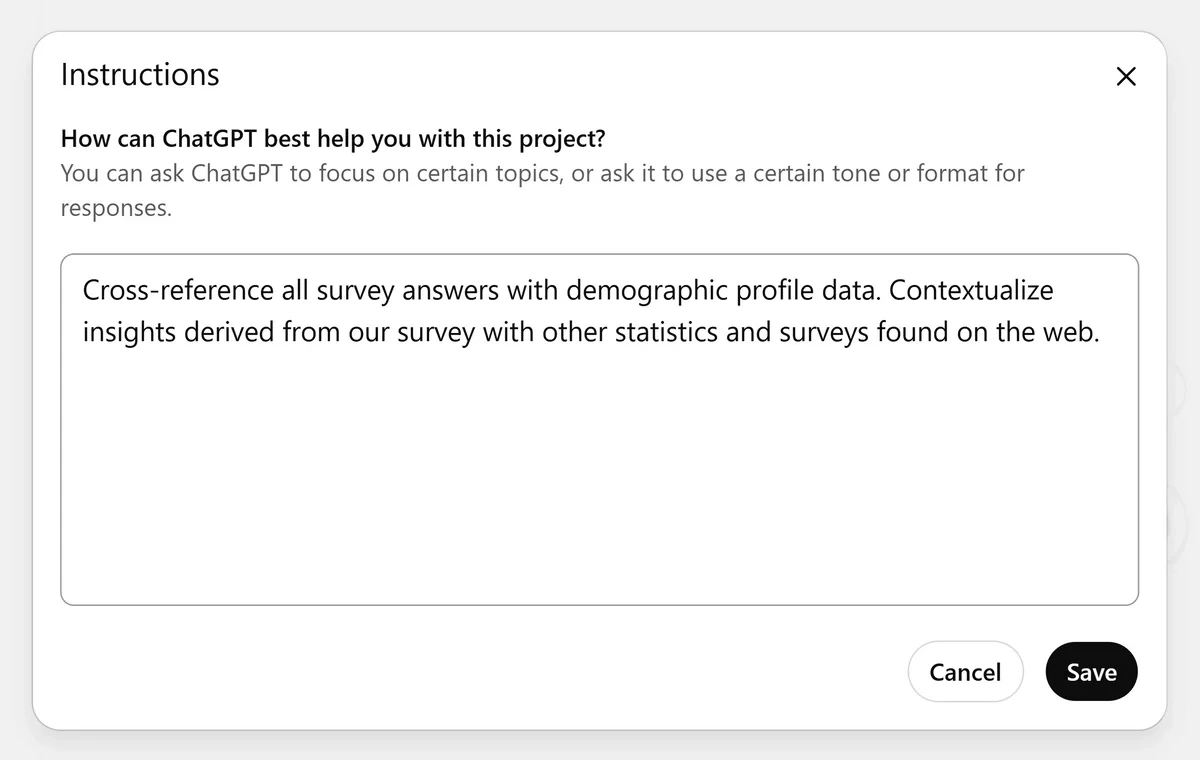
Crucially, you can add multiple external sources.
The LLM will retrieve information from these files as needed when answering your questions across any chat under your project.
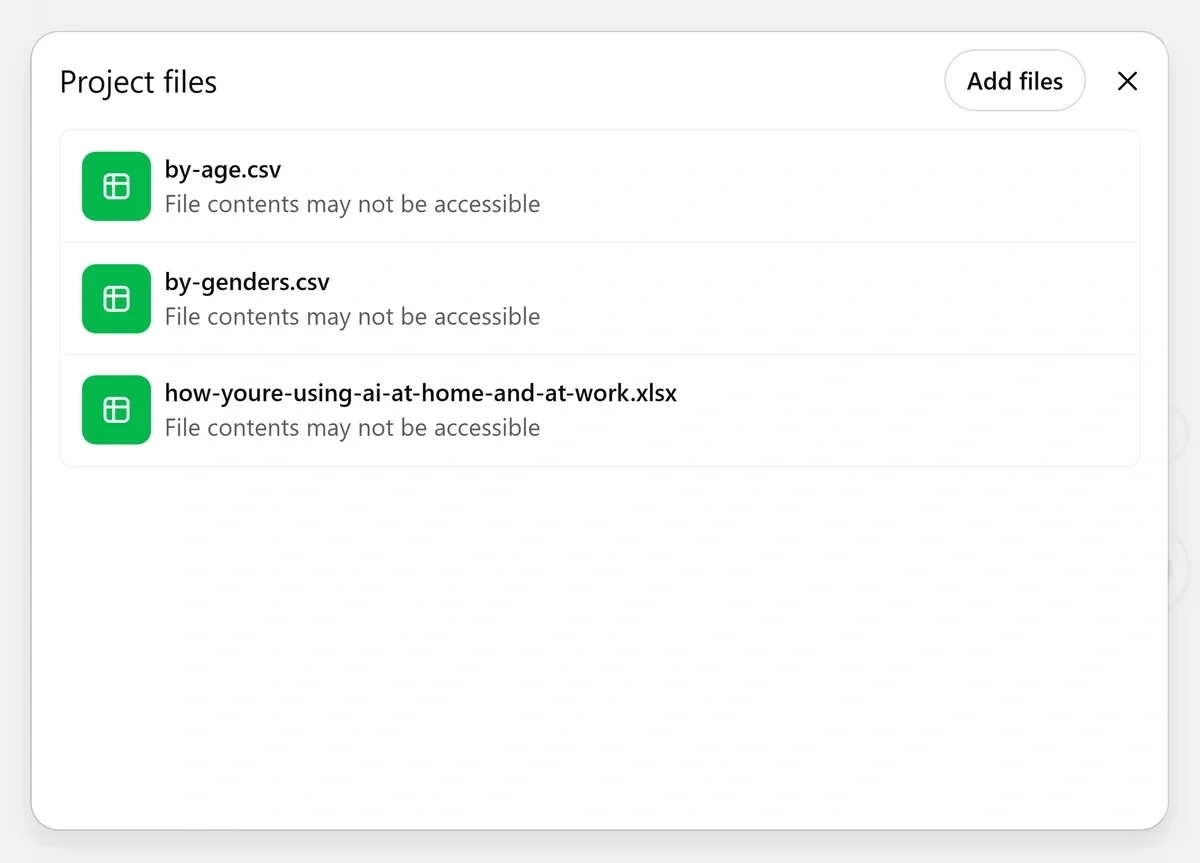
Context engineering benefits from stored memories so AI can access other chats and files from the project to steer its future answers.
The more you chat, the better ChatGPT will get at understanding what you’re asking of it and the less likely it is to be distracted.
ChatGPT also gives you access to other tools and apps with connectors.
You can set up a custom connector using a Model Context Protocol (MCP) server to directly load additional context from an app before ChatGPT answers your questions.
2. Claude
Claude also features a workspace-style Projects feature, as I noted in the examples shared earlier.
You can upload your system instructions and project files for a recurring task. Claude will use these details as the context for each chat.
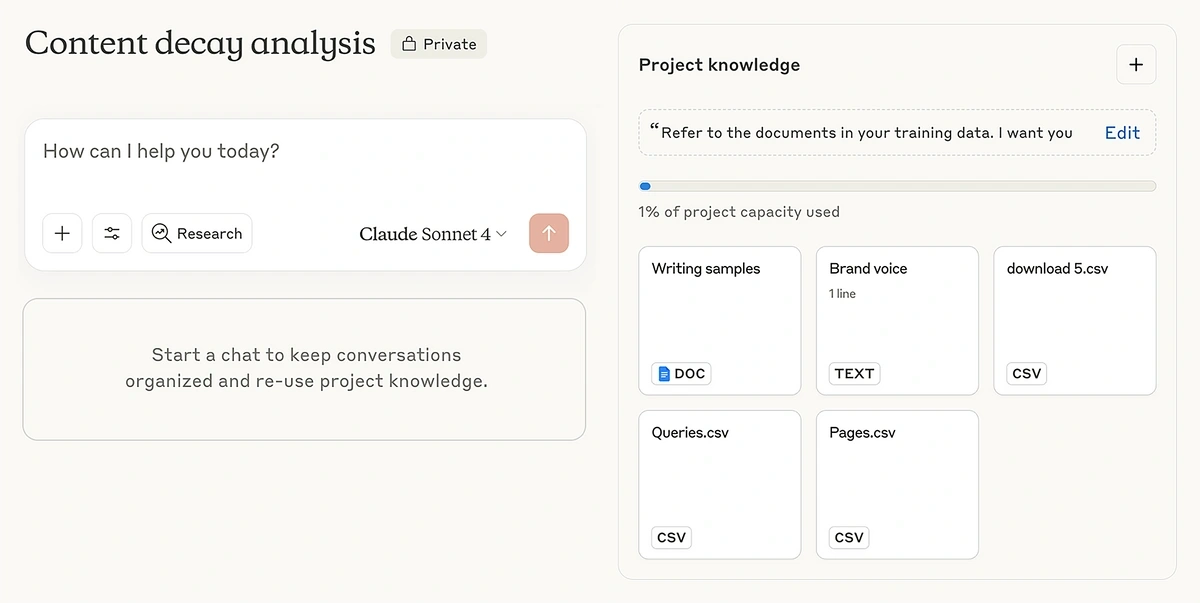
Claude can automatically switch between different context handling techniques depending on how extensive your project knowledge is.
It can leverage its large context window to pull the entire project knowledge with your prompt if it’s within the limits.
Once the context grows too large, Claude switches to RAG to manage the context window more efficiently, retrieving only the necessary info required to answer your request.
Claude works really well with MCPs too.
These MCPs are ideal for obtaining data from one or more apps.
The data is automatically pre-loaded into your prompt so Claude can give you the most up-to-date and helpful answer without vague guesses or hallucinations.
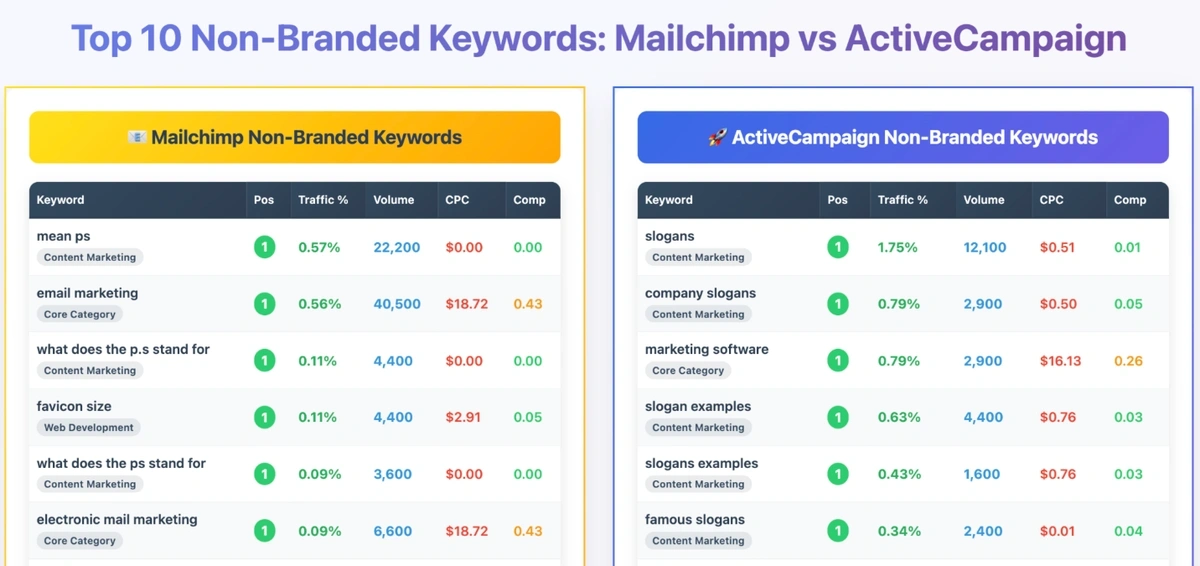
Using Claude with the Semrush MCP is a good example.
You can also enable memory in Claude so it can use your past chats to understand the context of your prompts better.
Memory is especially useful in Projects.
Having a separate memory for your Project focused on SEO means there’s no risk for that specialized context to bleed over to your CRM Project and so on.
Want to Spy on Your Competition?
Explore competitors’ website traffic stats, discover growth points, and expand your market share.
3. NotebookLM
NotebookLM is an entirely RAG-centered version of Google’s Gemini, tailored for research and note-taking tasks.
You add a bunch of documents as sources, and NotebookLM retrieves relevant information from your connected files to ground all its answers.
NotebookLM really shines when you’re working on a project where you need multi-document search capabilities and the ability to chat with your sources.
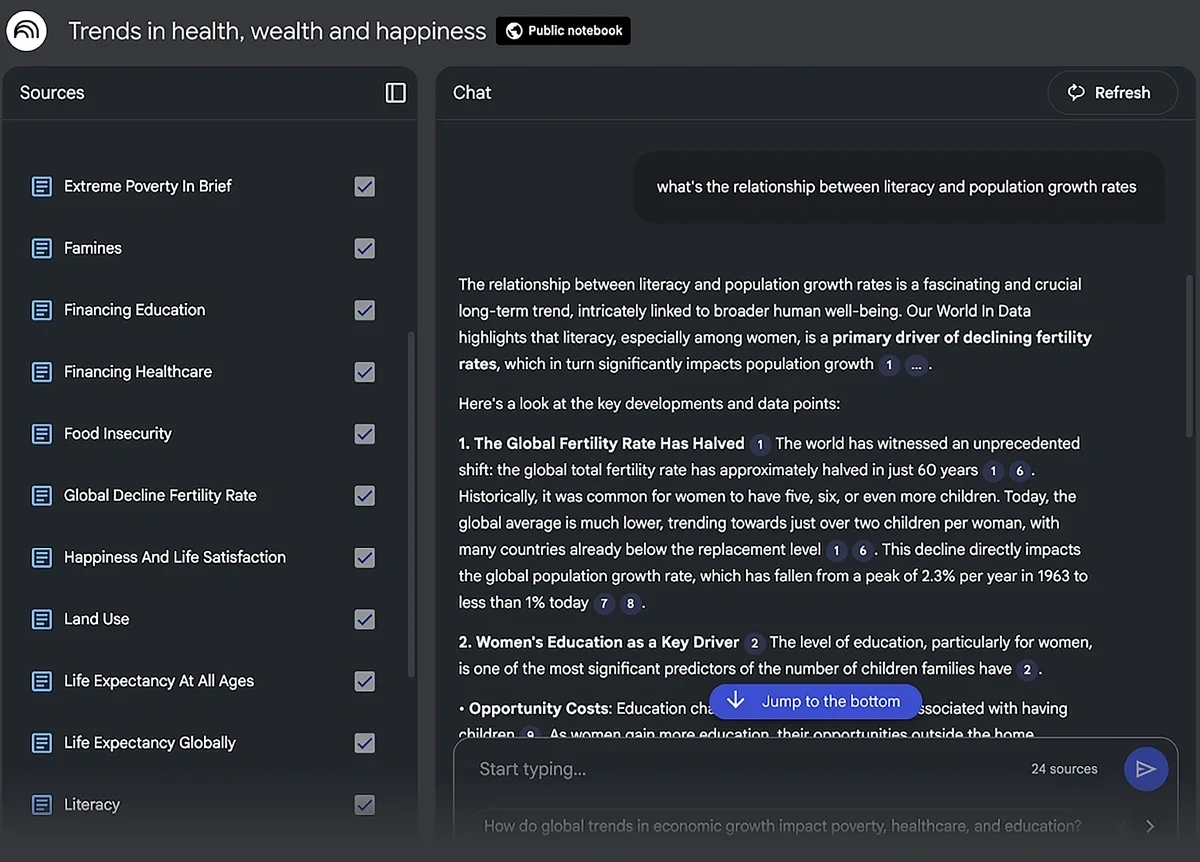
I think the output options are some of the coolest in NotebookLM. It can turn your data sources into:
- Video overviews
- Podcast-style audio
- Briefing docs
- Mind maps
These features do a fantastic job of summarizing large amounts of data into your preferred format.
I like that you include or exclude any sources from your notebook as you converse with the AI.
That way, you can set contextual boundaries for AI on the go, making it ignore or consider specific sources in your project.
4. TypingMind
TypingMind is a tool that lets you use any popular LLM tool in a chat UI that supports several features for context engineering. These features add more flexibility than what you’d often get from an LLM directly.
For example, you can create a knowledge base that can be accessed by any LLM of your choice (ChatGPT, Claude, Gemini, Grok, etc.).
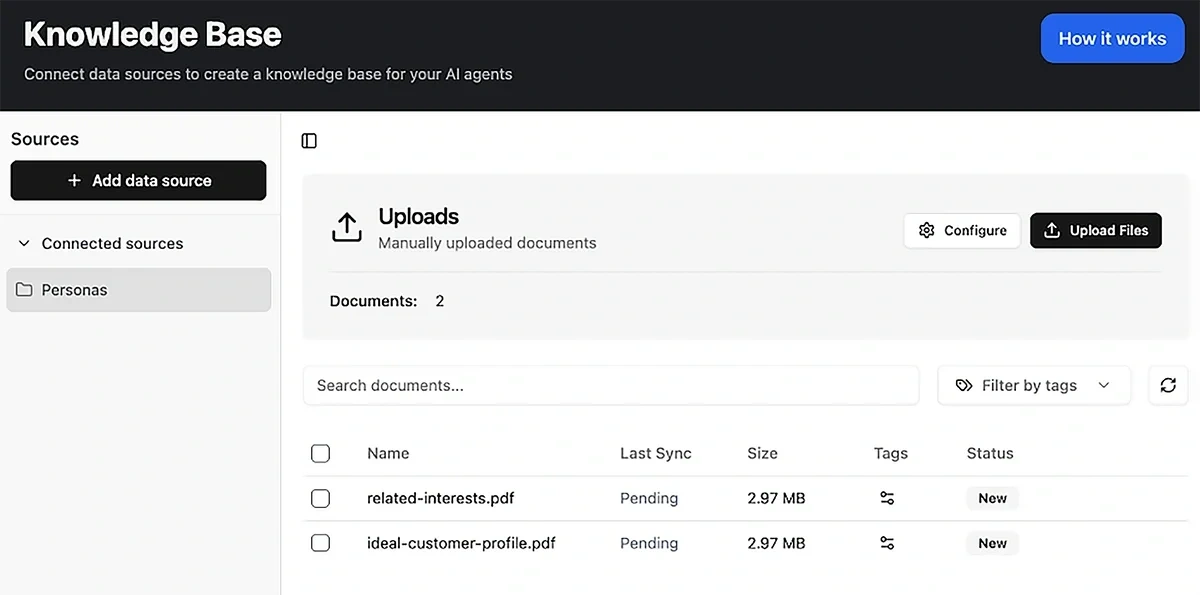
Plus, the ability to choose which plugins your LLM should have access to gives you precise control over the model’s contextual environment.
That means you can enable an HTML renderer tool if you’d like the LLM to generate its output in HTML.
Or if you need to extract specific info from a web page, there’s a specialized extension for that.
The same goes for connecting your LLM with Google web search or image search, depending on the exact context that makes sense for your task.
TypingMind also supports MCPs with local as well as remote servers.
Context engineering works best as a dynamic system where the AI has access to the required tools and domain-specific knowledge to produce tailored responses for your use case.
It’s why TypingMind is a great tool for establishing context with precision.
5. Perplexity
Perplexity lets you set up a workspace with all your relevant files and sources attached for the LLM to reference in its responses as needed.
It supports local files uploaded from your device as well as web links.
So if you wanted to connect Perplexity with the online documentation about your product, for example, you could provide the links to your web sources.
This is especially handy if your context environment is a mix of static files and web links that Perplexity can search and pull details from when answering questions.
The Likely Future: A Convergence of Long Context and RAG
Prompt engineering and context engineering aren’t mutually exclusive.
You don’t have to pick one technique and abandon the other.
As the development of new models like ChatGPT 5 shows, AI architecture is moving toward a unified approach for optimal LLM performance.
The best results come when you apply the right technique for the right job:
Well-structured, detailed prompts for simpler one-off tasks (prompt engineering)
And systematic context files in the form of background details from multiple sources, tools, APIs, and historical knowledge for complex tasks that you regularly come back to (context engineering).
Continue exploring with these examples of context engineering in marketing.
Stop Guessing, Start Growing 🚀
Use real-time topic data to create content that resonates and brings results.
Exploding Topics is owned by Semrush. Our mission is to provide accurate data and expert insights on emerging trends. Unless otherwise noted, this page’s content was written by either an employee or a paid contractor of Semrush Inc.
Share
Newsletter Signup
By clicking “Subscribe” you agree to Semrush Privacy Policy and consent to Semrush using your contact data for newsletter purposes
Written By


Osama is an experienced writer and SEO strategist at Exploding Topics. He brings over 8 years of digital marketing experience, spe... Read more